
Descubre todos los datos que Google y Facebook tienen de ti. Te conocen mejor que tu propia familia.
Ambas empresas cimentan su imperio sobre la materia prima más valiosa de la tierra, los datos. Información que les vamos dando acceso cada vez que usamos sus maravillosas aplicaciones, que casi siempre nos resultan gratuitas. Pues bien, cuando en internet no pagas por algo, habitualmente significa que el producto eres tú. En este caso, tus datos: de comportamiento, consumo, personalidad o contacto. Este conocimiento que Google y Facebook tienen de ti, lo usan para dar una experiencia más personalizada y crear nuevos productos más adaptados; pero también para convertirse en los principales proveedores de información para la industria publicitaria.
Se puede discutir sobre la bondad para el usuario de este acuerdo escrito, pero inconsciente. Pues todos hemos aceptado extensísimos textos legales, sin leer y comprender la extensión de la información que compartimos. De cara a arrojar luz que nos aporte más consciencia sobre este acuerdo, voy a intentar en este post en desvelar todas las cosas que Google y Facebook saben de ti.
Todos los Datos que Google tiene de ti.
Obvíamente, Google no se limita sólo a su famoso buscador. Para entender su alcance debes añadir todas los datos e interacciones que haces a través de Gmail, Maps, Chrome, Android, Google play, G+, Drive, Youtube o Waze.
Google te ofrece una sencilla opción de para conocer la información que dice utilizar para mostrarte anuncios, en mi caso mi sexo, rango de edad y simplemente unos 70 temas que supuestamente me interesan, que van desde las artes a los concursos televisivos… aunque creo que el último que vi, ha sido el precio justo. Muy decepcionante, Mr. Google.

Sin embargo, si ejerces ante Google tu derecho legal de acceso a todos los datos que tienen tuyos recibes una base de ficheros con unos 10Gb de peso. Esto si es alucinante, pues toda tu actividad aparece registrada y ordenada en su carpeta (ver imagen).

A través de estos archivos puedes consultar todas las búsquedas que has hecho desde 2007, todas. Obviamente también sabe tu teléfono, email, dirección de trabajo, amigos, dónde has sacados tus fotos y qué periódicos o blogs lees. Si accedes al historial de ubicaciones, tiene las coordenadas de todos los sitios por donde has pasado y es capaz de predecir si ibas a pie, en tren o en coche.
En el apartado YouTube está toda la información de los videos visualizados o subidos, todas las búsquedas y comentarios, así como los metadatos de cuánto tiempo de video he visto de cada video. Y esto sólo es el principio, muchos hemos visto la potencia de su asistente de inteligente artificial, capaz de pedir una pizza en tu nombre. Una herramienta en continua escucha de lo que dices y capaz de convertir tus instrucciones vocales en datos estructurados.
Debo de decir que me encantan los productos de Google: que me avise del tráfico antes de salir del trabajo a casa o que me de resultados personalizados. Llega un punto, que casi espero que lea mi mente, y siempre que uso su buscador me impaciento si a la segunda palabra no acierta en rellenar mi búsqueda. Entiendo que esta no sea la opinión de todo el mundo, pero yo estoy contento compartiendo mi información con Google pues eso supone un beneficio en mi vida.
Todos los Datos que Facebook tiene de ti.
Facebook recibe más de 2,5 millones de piezas de contenido cada minuto de sus más de 2,2 mil millones de usuarios. Sin embargo, Facebook es más modesta que Google y los datos que reconoce tener tuyos son menos asombrosos. Asegura que no cruza los datos de Facebook con su otra joya de la corona Whatsapp. A pesar de que sospechosamente te recomienda como amigos gente que sólo tienes en común haberte cruzado un mensaje con ellos.
En su favor, he de decir que si te da una opción muy sencilla y directa para descargar una copia de toda tu información en Facebook. Lo hice con mi cuenta y a pesar de que no soy nada activo en Facebook, mi archivo pesaba unos 300Mb, conteniendo todas las fotos, mensajes, likes o comentarios que había realizado.
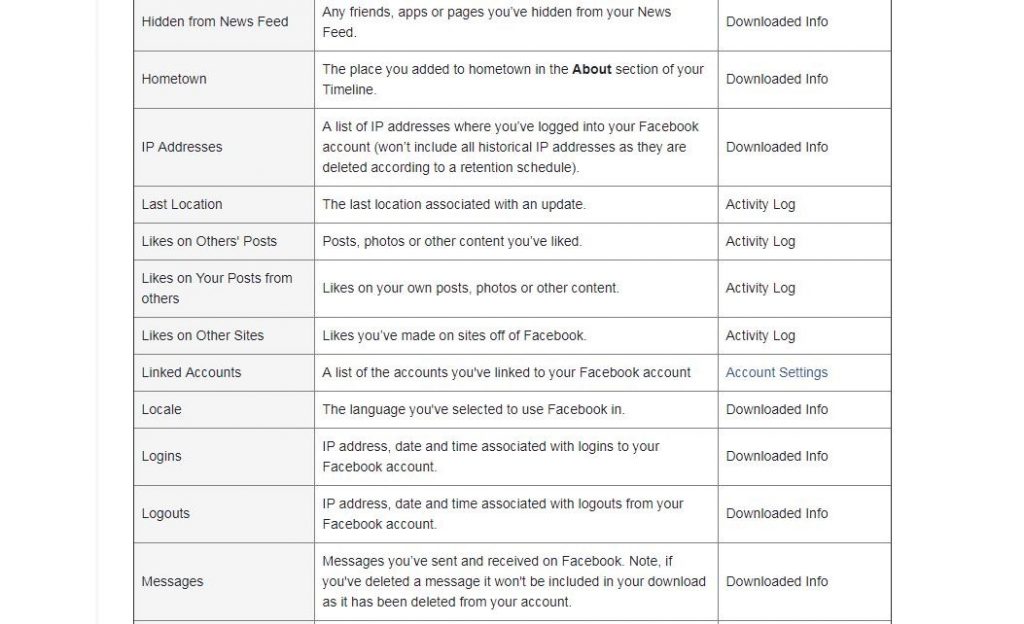
Facebook se ha metido en algún que otro problema por su falta de rigor en el uso de los datos que tiene de nosotros. El más reciente, el conocido como “facebookgate” (aquí una explicación de lo sucedido desde DataCentric), que se produjo debido a que Facebook permitía a terceras empresas acceder a datos de sus usuarios e incluso de sus amigos, a través de sistemas de autenticación como Facebook connect. Pero qué interés tenía FB en dar acceso a su información a estas empresas, pues bien, además de hacer su entorno más atractivo para los desarrolladores, el que te tengas que logar a FB para acceder a otras aplicaciones, aumentando con ello la trazabilidad sobre tu comportamiento.
Asimismo, hay multitud de testimonios que aseguran que Facebook e instagram te escuchan, desde el micrófono de tu móvil, y procesan esa metadata en datos estructurados que luego usan para perseguirte con publicidad de productos sobre los que has comentado que te interesaban. Pero este hecho siempre lo ha negado la compañía, aunque en muchos artículos se ponga en duda su versión.
El interés de Facebook en acumular más datos no parece basado en el objetivo de darnos una aplicación personalizada y dirigida en lo que aprende de nosotros, sino sobre todo en ofrecer a los anunciantes unas posibilidades de segmentación que sobrepasan lo inquietante. Por ejemplo, dentro de Facebook ads he creado una segmentación de prueba usuarios varones de más de 18-65 años, en Madrid, interesados en el PP, Siria o el Islam. El filtro me arroja una audiencia de 350.000 usuarios que Facebook me propone impactar con mi publicidad.

Según un estudio de Accenture Digital, el 83% de los consumidores están dispuestos a dejar sus datos para permitir una experiencia más personalizada. En mi opinión aquí estaría la clave: desarrollar esta propuesta de valor para el usuario en el uso de sus datos y ganar su confianza de que sus datos los gestionarás de una manera ética, garantizando su seguridad y privacidad.
Gerardo Raído
Chief Digital Officer en DataCentric

