¿POR QUÉ DESCARGAMOS INTERNET?
En cierta ocasión, leí que una empresa se anunciaba con el siguiente lema “La mejor base de datos es internet” En su momento, hace unos 5 años, la frase sonaba fenomenal, pero hacerlo realidad era francamente difícil y era consciente de que quien lo decía no tenía ni idea de su complejidad técnica.
Con los años mi tesis se demostró. Aquello que sonaba fenomenal a nivel comercial era, a nivel técnico, un invento muy básico para aproximarse a los datos de internet.
Por otro lado, desde hace años pienso que la mejor información sobre una empresa la puedes encontrar directamente en su página web. Ahí las empresas describen quiénes son, qué hacen o donde están.
Desde hace años, trabajo haciendo bases de datos de empresas y conozco las virtudes y los defectos de los depósitos de cuentas, de los códigos de actividad económica y todos los enfoques tradicionales para generar bases de datos y conocimiento sobre empresas.
SENTEMOS LAS BASES
Aunque suene muy crítico, el 95% de las empresas que dicen hacer crawling (descargar datos de internet) trabajan con softwares comerciales de scraping. Esto consiste en entrar en una página web y descargar una serie de datos estructurados contenidos dentro del mismo dominio o URL. Por ejemplo, entrar en la página web de la administración y descargar las direcciones y teléfonos de los ayuntamientos.
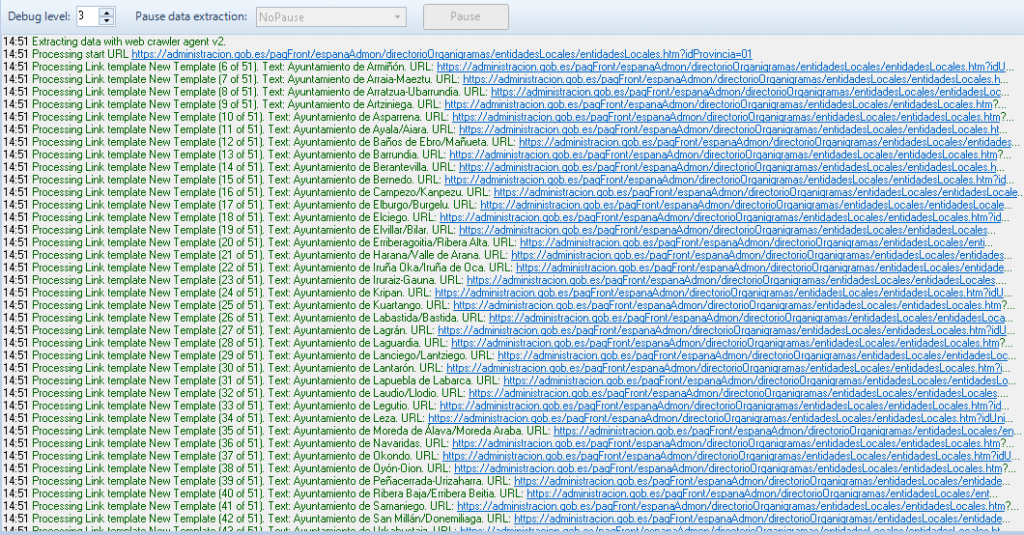
De estos actores, una parte importante se dedica a este mismo trabajo sobre páginas web con derechos de propiedad intelectual; por lo que además de tener poca complejidad técnica, en muchos casos es una actividad de dudosa legalidad. Existe toda una industria de empresas que descargan perfiles de Linkedin u hoteles de Booking.
Crawling, del inglés gatear, consiste en la descarga de información de forma masiva para posteriormente indexar el contenido de un conjunto de páginas web no estructuradas. Hacer esto tiene una elevadísima complicación técnica y no existen softwares comerciales, más allá de las herramientas de Google que lo realicen de un modo profesional. De hecho, una parte muy importante de la gente que de verdad hace crawling acude a Common Crawl (un proyecto donde actores comparten una base de datos con índice de una versión de internet relativamente actual y exhaustiva) o a Google.
Podríamos decir que, en el mundo de internet y datos, Google y Amazon son quienes llevan la delantera, pero aquí empieza la parte bonita de la historia.
Cuando empezamos a descargar internet comenzamos como todo el mundo: primero hicimos scraping con un software básico, luego fuimos a Common Crawl y a Google hasta que, fruto de nuestra curiosidad, llegamos a una serie de proyectos de software libre que surgieron con Lucene a final de los 90 y que han evolucionado hasta nuestros días.
Si el tiempo fuera gratis, todo lo que os vamos a contar es casi gratis. Solo tiene un pequeño coste en Amazon Web Services.
VER CÓDIGO FUENTE
Casi todos los navegadores tienen una función para ver el código fuente de una página web.
Nuestro objetivo es descargar toda esta información y guardar dicho contenido de modo masivo en una base de datos.
Y aquí empieza nuestra aventura…
Las páginas web tienen contenidos estructurados orientados a los navegadores, como pueden ser:
- Título: La pestaña con el nombre de la web.
- Descripción: Las líneas que aparecen en la lista de resultados de una búsqueda en un navegador debajo del título.
- Keywords: Las palabras clave a las que queremos dar un peso específico para que nos encuentren.

Descargar esta información es relativamente sencillo, pero resulta que no todas las páginas tienen estos datos informados o que dentro de un dominio los tiene informados de distinta manera. Por ejemplo, muchas webs tienen una versión en inglés y otra en español o keywords distintas para cada sección.
Luego está todo el contenido no estructurado. La página web de una peluquería de barrio no tiene absolutamente nada que ver con la de la Universidad Complutense de Madrid.
¿Cuál es la parte más relevante del contenido? ¿Cómo descargar la web de una universidad y no tumbar la web de la peluquería? ¿Qué ocurre cuando alguien utiliza un juego de caracteres no estándar, por ejemplo, el japonés?
Tras encontrar la tecnología básica para descargar datos, tuvimos que aprender a parametrizar, equilibrar y realizar cientos de pruebas de concepto para comprobar si realmente estábamos descargando la información que queríamos dentro de una página web.
Para que esto funcionara de modo correcto tuvimos que definir distintas tipologías de webs:
- Webs donde hay que hacer scraping para extraer una información precisa (una franquicia o un ministerio)
- Webs que son centros de beneficio para las empresas y que normalmente tiene protegida su descarga (Facebook, LinkedIn, etc)
- Parking de dominios
- Webs de empresas (con una estructura relativamente estándar: inicio, quiénes somos, Contacto, Servicios, etc)
- Páginas web con contenido para adultos o no relevante
- Páginas sin interés como blogs personales
Por otro lado, un porcentaje de las webs se caen periódicamente, por lo que hay que rastrearlas constantemente por que puede que un día estén en pie y otro tumbadas.
¡Estábamos construyendo una auténtica “araña” para crawlear de verdad!
PERO, ¿QUÉ ES INTERNET?
Esto es una pregunta cuasi filosófica. Hace muchos años intentamos salir a internet a nivel de IP. Aquello no terminó bien ya que empezábamos a entrar en páginas no indexadas pertenecientes al Dark Internet. El internet que conocemos es un protocolo de comunicaciones (actualmente estamos en HTTP/2) donde las IPs son, por decirlo de modo sencillo, los “números de teléfono” de internet o las “matrículas” de una web.

Los servidores DNS son los encargados de convertir estas IPs en una URL fácilmente recordable.
¿Cómo conseguimos una base de datos con todas las urls donde mandar a nuestra araña? Nuestra araña es ciega y tenemos que darle un camino. Hemos probado a mandarla a nivel de IP y no es sostenible, y seguir los links entre páginas no garantiza una descarga exhaustiva, así que la única solución era crear una super base de datos con todas las URLs y categorizarlas según la tipología anterior.
Finalmente, la conclusión a la que llegué es que convertir internet en una base de datos es complicadísimo porque nunca sabes qué parte de internet tienes y cuál no.
Y AHORA, ¿QUÉ HACEMOS CON TODO ESTO?
Un día teníamos una araña descargando internet de modo óptimo y guardando los datos en un sistema de ficheros básico no explotables/accesible. Podíamos consultar una a una las webs para ver las descargas, pero para entender el capítulo anterior queríamos tener una visión global de qué estábamos haciendo y necesitábamos alguna base de datos que permitiera guardar y consultar esta información de modo masivo. Ni Oracle ni Postgree soportaban este uso.
Probamos sistemas de BigData como Kassandra, SolR o Elastic Search y finalmente optamos por combinar distintas herramientas: SolR y Elastic Search para indexado y consulta, y Oracle para la gestión del SmallData y algoritmia precisa a nivel de token.
Así, podíamos tener distintos módulos:
- Una base de datos que guardaba los itinerarios de la araña. Básicamente un repertorio de URLs con mucha información asociada: Tipología de la web, fecha de la última descarga, resultado y un montón de datos estadísticos como cuántos enlaces tiene, tecnología que utiliza, número de secciones, idiomas que maneja, etc.
- Una gran base de datos o índice con la última versión de la información descargada y un histórico de cambios.
- Una base de datos relación donde poder guardar las direcciones, teléfonos, horarios de apertura y todo aquel contenido que podemos estructurar.
Este último punto es la clave de todo. Internet es un montón de información no estructurada y nuestro objetivo es estructurarlo para poder accionarlo como una base de datos. Aquí hemos utilizado mucha tecnología y lenguajes como Python o R para optimizar procesos. Aunque el equipo hacía auténticas maravillas con expresiones regulares en PLSQL corriendo sobre campos Clob en Oracle.
ESTO FUNCIONA PERO ES INGOBERNABLE
Ahora que funcionaban todas las piezas tocaba engarzar los procesos y automatizarlos.
Teníamos claros los instrumentos de nuestra orquesta, todos sonaban muy bien y, como decía un compañero, hacíamos las mejores jam sessions pero queríamos trabajar como una orquesta sinfónica para poder ofrecer el producto que queríamos.
Hemos dedicado meses o incluso años a diseñar flujos de trabajo, optimizar procesos y automatizar tareas para invertir el mínimo tiempo posible a optimizar las descargas y la algoritmia.
AHORA SOMOS EXPERTOS
Tras muchas horas de jam sessions hemos afinado nuestras técnicas de crawling y ahora tocamos con soltura los clásicos. Ahora sí que podemos decir que la mejor base de datos es internet. Además, casualmente, el core de Datacentric es el suministro de datos.
El primer uso que hemos dado a esta tecnología es alimentar nuestras propias bases de datos con atributos como URL de un establecimiento, teléfonos u horarios de apertura.
Luego, hemos creado bases de datos de segmentos exclusivos. Hicimos un proyecto para identificar tiendas online/ecommerce a través de técnicas como un scoring que dan peso a palabras como Carrito de la compra o Finalizar pedido. También hemos identificado empresas de alquileres o hemos buscado gemelos a los mejores clientes de nuestros clientes, que en cierto sentido es una derivada de lo anterior.
Antonio Romero de la Llana
Consejero Delegado de DataCentric