¿Qué son los datos identificativos de una empresa?
Los datos identificativos de una compañía son cualquier información relativa a ese negocio que nos lo identifique unívocamente, o que al menos nos ayude a hacerlo.
El principal dato identificativo único de una empresa en España es el CIF (Código de Identificación Fiscal) o el NIF (Número de Identificación Fiscal) en el caso de los autónomos. Es considerado como el dato clave más potente para relacionar información empresarial. En ausencia del CIF, hay muchos otros datos empresariales que nos ayudan a identificar o asegurar que estamos hablando del mismo negocio, como podría ser su número de teléfono o web. Es importante usarlo en conjunción con otros datos, pues el negocio puede tener varias webs o teléfonos, o perder su número de teléfono o web.
Ejemplo de Datos identificativos de una empresa en España:
CIF
Cuenta de cotización a la SS
URL o pagina web
Razón Social
Dirección postal
Números de teléfonos
Emails Corporativos
IPs
A partir de estos datos podremos relacionar nuestros datos de empresa con mucha otra información descriptiva de una empresa, que nos ayudarán a caracterizarla. Consulta nuestras posibilidades de enriquecimiento de información empresarial. De esta manera podremos llegar a tener una información completa de esa empresa.
Datos de Intención ¿Qué es intent data y, sobre todo, para qué sirve?
Los datos de intención, o intent data, son conjuntos complejos de datos que, tratándolos de modo adecuado, se convierten en información capaz de predecir los intereses de compra de los potenciales, ya sean estos empresas o personas, en el futuro inmediato o en el corto plazo. La base para poder realizar el análisis predictivo de estos datos no es otra que en base a su comportamiento o búsquedas realizadas. Poder impactar a un potencial cuando se encuentra en la parte baja del embudo de conversión, correspondiente a intención, multiplica por más de 5 la respuesta.
Pongamos un ejemplo práctico: en el caso de que seas SEAT y puedes impactar dos potenciales. Al primero de ellos, Paco, le interesan los coches y a la segunda, Marta que no le interesan, pero quiere renovar su vehículo porque el actual está dándole problemas. Es evidente que, a SEAT le interesará más Marta, que tiene una intención de compra más cercana y definida en el tiempo. Sabemos que a Paco le gustan los coches, pero por mucho que le interesen lo más seguro es que no esté comprando coches constantemente. Es decir, los datos de intención permiten poner el foco en aquellos prospectos más preparados para realizar una acción de compra de un producto o servicio determinado, y no malgastar esfuerzos en aquellos que aún no lo están.
¿Cómo podemos inferir esa posible intención de compra?
Existen múltiples vías datos de comportamiento, búsquedas, patrones de correlaciones o una combinación de todo ello. Si continuamos desarrollando el ejemplo anterior Google Ads ofrece la segmentación de interés en compra de coche en base a búsquedas; pero también si SEAT directamente o a través de un proveedor tiene usuarios geolocalizados con una app puede detectar esa necesidad, cuando el cliente potencial visita un concesionario de la competencia o un taller mecánico en repetidas ocasiones.
Está claro que todos los intent data no son igual de valiosos. Hay momentos críticos que pueden desencadenar información muy valiosa para múltiples compañías. Por ejemplo, si identificamos a usuarios con la intención de mudarse de casa, identificamos un momento muy importante en el que se deciden muchas contrataciones y compras. Estos datos de intención de compra de vivienda, podrían activarse desde grupo Tinsa, a través de la identificación de usuarios que piden valoraciones de viviendas. Descargar E-book “Las ventajas del uso de datos inmobiliarios para el marketing y la toma de decisiones”.
En el ámbito B2B, donde el viaje a la compra suele ser más largo e involucra a varios decisores, el intent data gana especial protagonismo. Si DataCentric, registra has leído este artículo, descargado el Ebook anterior y has clicado en una campaña sobre datos de intención, se te asignaría un grado de madurez suficiente en el embudo de conversión para activar acciones de marketing o incluso comerciales directamente.
Tipos de datos de intención
Existen dos tipos principales de Intent Data, los correspondientes a First-Party (datos propios) y a Third-Party (modelizados y suministrados por un tercero).
Los datos de intención propios (First-Party)
Son los más potentes pues se construyen con tu propia información y no tienen coste. Los mismos pueden ser recogidos de varios orígenes:
Datos declarativos recogidos en tu propio CRM
Datos comportamentales sobre visitas web, descargas de ebook, apps
Respuestas a campañas
Información proveída desde nuestro contact-center de atención al cliente
Los datosde intención de Tercera parte (Thrid-Party)
Provienen de compañías que, recopilan datos y comportamientos de distintos orígenes, y los agregan para usarlos con fines publicitarios. Estos datos si tienen coste, y es importante conocer su cumplimiento de las leyes de privacidad y usar solo proveedores fiables en cuanto a sus metodologías de recolección de la información.
La mejor estrategia de datos detrás del CRM para impulsar tu negocio
1. El dato, la información y el CRM
La información es un conjunto de datos que se procesan de manera significativa de acuerdo con un requisito dado que luego da lugar a tablas, listados y gráficos comprensibles.
Por tanto, los datos son cadenas de información en bruto que por sí solas transmiten muy poca información. Como piezas de un puzzle que hasta que no se juntan son difíciles de comprender del todo.
Llevado a un CRM el dato es la base de la información contenida. Un elemento que sustenta una frágil estructura de la que depende la calidad de la gestión comercial, y por ende, las ventas presentes y futuras de una compañía.
Es primordial por tanto enfocar nuestra energía a la base de la estructura si queremos mejorar las estrategias de negocio que salen del CRM. En función de la calidad de los datos, obtendremos una calidad de información proporcional que nos permitirán tomar decisiones más efectivas.
2. Calidad y consumo del dato
El ciclo de vida del dato
Antes de su consumo en el CRM el dato debe pasar por distintas etapas. Estas etapas son procesos que garantizan el mantenimiento de la calidad del dato hasta su uso.
Identificación
Saber qué buscar y cómo buscar. Podemos hablar de identificar fuentes internas o externas a las organizaciones en función de las necesidades.
Extracción
Es una fase que puede implicar varios departamentos desde legal & compliance por temas de protección de datos o IT por temas de interconexiones entre sistemas y seguridad de la información.
Normalización
Si los datos provienen de fuentes diferentes, es muy probable que sea necesario un proceso de normalización para homogeneizar su uso y permitir operaciones de agregación y correlación.
Etiquetado
El etiquetado del dato se puede asemejar a su nombramiento o a su clasificación. De allí saldrá el rol del dato para la información que queremos que vincule.
Relación
Podría ser la parte del tratamiento del dato más importante. El cómo conecta con los demás datos para la transformación en información útil.
Almacenamiento
Será necesario su almacenamiento, aunque sea de forma temporal para su transformación en información.
Distribución
Podemos compartir el dato cuando este etiquetado o esperar que sea ya parte de un conjunto de información. Tener la capacidad de ofrecer canales para el consumo del dato es necesario para poder explotar todo su potencial de manera transversal en toda la organización.
Actualización
Algunos datos con el paso del tiempo pierden valor. Para evitarlo se aplican procesos de búsqueda y actualización de cada dato.
De acuerdo con la analogía anterior podríamos decir que trabajar en todas las etapas del ciclo del dato es fundamental para obtener todas las piezas del puzzle.
Sin embargo, los CRMs por su naturaleza conectan con fuentes de datos, pero no son softwares para procesar datos. Las fuentes de datos por su lado generan datos en bruto que normalmente procesan los datos lo justo y necesario para ser transferidos.
En consecuencia, nos encontramos que habitualmente se conectan las fuentes de datos directamente con los lugares de consumo del dato transfiriendo datos poco precisos o de baja calidad.
Consumo del dato Data as a Service (DaaS)
Los diferentes departamentos de una empresa tienen necesidades diferentes en cuanto a qué datos quieren consumir, cómo los tienen que consumir y la cantidad que necesitan para mejorar la toma de decisión.
Para dar respuesta a las diferentes necesidades de consumo del dato nace Data as a service o DaaS. El término hace referencia a servicios cloud que proporcionan una infraestructura totalmente flexible para conectar con diferentes fuentes de datos y aplicaciones de consumo de datos como el CRM para el uso de estos con agilidad y precisión.
Pero no solo eso, sino que además proporciona un entorno perfecto para el almacenamiento, procesamiento y / o análisis mejorando el ciclo del dato en todas sus etapas.
La principal ventaja del DaaS es la capacidad de relacionar datos de diferentes entornos y diferentes ecosistemas para crear información personalizada en función de las necesidades de cada consumidor de datos.
Ventajas
Dato siempre al día
Se consumo solo lo que se necesita
No hace falta una infraestructura muy compleja ni costosa
Puesta en marcha rápida
Flexibilidad
Coste optimizado
Orientado al negocio
Permite implementar metodologías de Data Ops
3. Calidad y consumo del dato
Veamos un ejemplo que nos permita entender mejor todo lo comentado anteriormente.
La empresa Mas deporte.S.L es una marca de artículos deportivos que cuenta con varios establecimientos en España. Su tendencia en ventas venia siendo plana desde hace algún tiempo y a raíz de un fuerte decreciemiento económico global la facturación comenzó a descender paulatinamente
La marca usaba un CRM como directorio de clientes. Disponían de una foto de cómo era la relación comercial, pero tenían dificultades para obtener los insights necesarios para optimizar la estrategia en función de los datos contenidos en el CRM.
¿Por qué no eran capaces de sacarle partido a su CRM?
Contaban con una única fuente de datos cuando implantaron el CRM proveniente de su tarjeta de fidelización.
Además, a posteriori de la implantación y a raíz de campañas de marketing para intentar crecer en ventas se generaron otras 2 fuentes de datos:
Proveniente de eventos deportivos donde cualquiera podía probar los artículos de la marca y conseguir premios y descuentos por ganar competiciones deportivas.
Proveniente de concursos y sorteos que hacían en redes sociales con deportistas de élite e influencers deportivos.
Esta situación generaba varias problemáticas en el CRM:
Con la implantación del CRM se configuró la integración automática de los datos de las tarjetas de fidelización. Sin embargo, las dos fuentes de datos añadidas a posteriori no tuvieron en cuenta en detalle el modelo de datos del CRM. Debido a la cantidad de datos y complejidad dentro del modelo esto derivaba en datos desactualizados y clientes duplicados con el campo dirección en diferentes formatos.
Tenían dificultades al segmentar y obtener extracciones fiables de la base de datos para analizar
No contaban con los datos suficientes para realizar perfiles avanzados de clientes y potenciales. Y las campañas comerciales resultaban muy genéricas con retorno bajo debido a la imposibilidad de personalizar los mensajes
Tenían datos desactualizado sobre sus clientes empresariales, en cuanto a número de empleados, actividades principales, direcciones…etc.
En resumen, por falta de calidad y precisión en los datos, los análisis carecían de sentido y no permitirán sacar conclusiones que mejorasen la toma de decisiones. Un CRM con malos datos nos lleva a un mal Customer Experience que se ve reflejado en los resultados de negocio.
Cómo fortalecieron su estrategia de datos para sacarle el máximo partido a su CRM
Tras trabajar en la normalización y estandarización de la base de datos del CRM se generaron preprocesos de calidad de datos a todos los datos provenientes de las fuentes que generaban datos duplicados y no estandarizados antes de su volcado en el CRM.
En segundo lugar, mediante conexión API y en servicio DaaS conectaron el CRM a Pyramid, el third party data de DataCentric. Habiendo normalizado el campo dirección del cliente se pudieron agregar más de 2500 indicadores de las diferentes zonas geografías a las que pertenecían sus clientes. Datos a nivel de sección censal como:
Estructura de los hogares
Distribución del gasto en salud
Renta bruta y renta disponible
Superficie de las viviendas
Ya enriquecido el CRM con nueva información el equipo de análisis se puso a trabajar en un perfilado avanzado de clientes juntando los datos nuevos con los ya existentes de la venta de artículos.
Los resultados del análisis permitieron obtener información de valor sobre entre otras cosas el nivel socio-económico, la importancia de la salud, el tipo de vivienda o la tipología de familia/hogar. Lo que en última instancia permitió en tiempo record:
Generar diferentes estrategias de captación, crecimiento y fidelización enfocadas a perfiles de clientes diferentes con necesidades diferentes
Establecer nuevos procesos de onboarding en función de la zona del cliente y su propensión hacia ciertos productos
Para aquellos productos más caros lanzar servicios de financiación complementarios en función de los riesgos de impago
Permitió un análisis de la red de tiendas para ver zonas de canibalización entre tiendas y poder optimizar costes
Produjo el descubrimiento de nuevas zonas potenciales en las que la marca podía enfocar el esfuerzo comercial con nuevas tiendas y acciones promocionales
La implantación de soluciones de oferta personalizada en base a datos en su ecommerce
Estas soluciones han sido claves en un incremento de nuevos clientes de 28% y en poder incrementar el ticket medio de compra un 17%.
Lo que nos enseñan cada día las grandes tecnológicas (Google, Facebook, Amazon, Apple, Netflix) es que accionando los datos que generamos por interacción con el usuario de forma correcta, tiene un potencial mayor que simplemente mejorar la experiencia de usuario.
España es el país europeo, y del mundo en 2017, con mayor penetración de smartphone con un 88% de penetración de mercado. En el camino para adaptarse a una sociedad y a un mercado que hoy en día es móvil las empresas multinacionales hacen esfuerzos por conectarse con sus clientes. Es común facilitar APPs para ofrecer un servicio complementario o facilitar la gestión de tu servicio desde un dispositivo móvil. Sin embargo, salvo que sea una app de pago por uso o transaccional (en la que se suele obtener una comisión por transacción) raramente conseguimos monetizar esos datos.
EL VALOR DE DATOS GEORREFERENCIADOS Y TEMPORALES
Pensemos en qué datos podemos sacar de una APP y para qué utilizarlos. Normalmente tenemos un email de registro que sirve como canal de contacto, los datos de navegación, que nos servirán para mejorar la experiencia de usuario y algunas apps, además, piden acceso a datos internos del teléfono como geolocalización, acceso al micrófono o a los bancos de imágenes. De estos datos la localización es el dato más potente al que podemos acceder. Si a las variables x, y de localización además sumamos la variable temporal, podemos sacar un conocimiento del usuario y del entorno suficiente para accionar estrategias basadas en datos que funcionen.
Pensemos que si un usuario pasa cierto tiempo en un centro deportivo de pádel de forma recurrente ¿no podríamos deducir que es aficionado al pádel y que es susceptible de recibir información sobre equipamiento deportivo específico? O si el usuario pasa varias noches en diferentes localizaciones de forma recurrente ¿no podríamos deducir que es una persona que viaja y que recibirá con interés información sobre seguros de viaje? ¿O sobre un seguro del hogar para su vivienda vacacional si la localización se repite y está en la costa? Indudablemente las campañas que hiciéramos tendrían mayor probabilidad de éxito.
A continuación, veremos cómo podemos extraer información de valor de la APP para poder integrarlo en nuestra estrategia data-driven a través del caso de uso de Pyramid Datalake. El Third Party Data de Datacentric que hemos usado para enriquecer y cualificar con precisión los datos de geolocalización extraídos de la aplicación.
CUALIFICACIÓN DE USUARIOS Y CONOCIMIENTO DEL ENTORNO
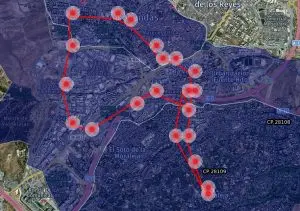
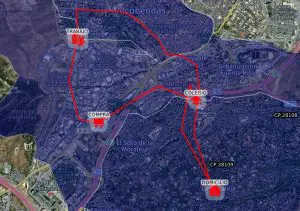
En este caso concreto hemos analizado la información georreferenciada histórica de un usuario en Alcobendas. Basándonos en lo que hemos comentado antes y analizando los datos hemos identificado unas localizaciones clave llamadas “keylogs”. Esas localizaciones son el lugar de trabajo, la vivienda, el colegio y el supermercado habitual.
Ruta del usuario a partir de datos georreferenciados
Keylogs identificados tras analizar el comportamiento del usuario
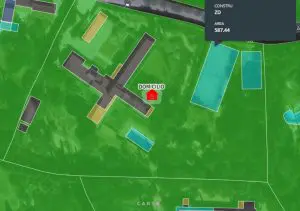
Tras analizar el comportamiento de 24h a 8h hemos definido el domicilio o vivienda habitual del usuario. A partir de aquí hemos enriquecido el registro con información de catastro contenida en Pyramid para perfilar más al usuario a través de los datos correspondientes a su parcela donde vemos que tiene una parcela de 10.000 m2 con la vivienda principal y otro edificio de 95 m2, una piscina, una pista de tenis y una pista de pádel. A continuación, hemos añadido datos agregados de la sección censal como el nivel socioeconómico, la media de edad, la tasa de morosidad, la superficie media de las viviendas, el año medio de construcción de la vivienda y el gasto en ocio.
Con estos datos ya podemos comenzar a inferir que el usuario puede ser un potencial cliente de marcas de lujo: el usuario es de clase alta, su gasto en ocio es alto y la morosidad es baja. Además, por su vivienda, puede ser posible cliente también de productos y servicios asociados al tenis, pádel, la piscina, accesorios de jardín, sistemas de seguridad etc…
Datos de la construcción de la vivienda - Área de la zona deportiva
Información agregada de la sección censal
Toda la información que seamos capaces de ir añadiendo nos permitirá validar la información anterior o crear una foto más precisa del perfil de usuario para identificar necesidades u ofertas adecuadas de nuestros productos o servicios
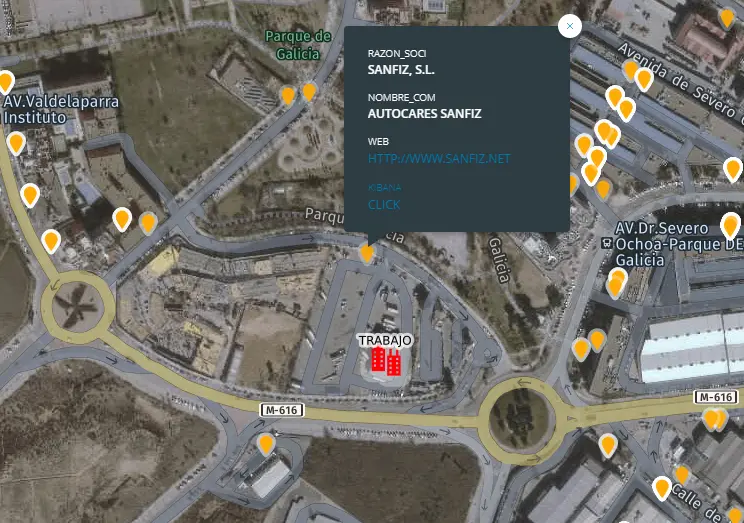
Siguiendo con el análisis vemos que de 9h a 18h la ubicación se corresponde con la localización de la empresa AUTOCARES SANFIZ y que se trata del lugar de trabajo del usuario. Gracias a Pyramid hemos vinculado la localización de la empresa con los datos contenidos en su web. En este caso simplemente es para poder hacernos una idea de la posible profesión del individuo, pero teniendo vinculada la localización de las empresas con su web nos ayuda a determinar la actividad real de la empresa que suele diferir de la que aparece en el registro mercantil. Muy útil si tenemos productos o servicios B2B para identificar las posibles necesidades de la empresa. Incluso para realizar segmentaciones por localización y por característica web. Por ejemplo, podríamos hacer una segmentación de todas las empresas de Alcobendas que además tengan linkedin en su web o que sean ecommerce. La creatividad e imaginación es el límite a la hora de segmentar.
Vínculo de la localización física con la web
Empresas localizadas y datos asociados
Volviendo al caso que nos ocupa, también identificamos un lugar de compra habitual del usuario al analizar los logs de datos de la APP y combinarlos con los datos de empresas y POIs (o puntos de interés) de los que dispone Pyramid y que nos permite identificar la tienda física con precisión.
Conocer dónde compran nuestros usuarios puede sernos de utilidad para saber qué retailer físico utilizar para servir nuestros productos y dónde invertir presupuesto y esfuerzos a la hora de realizar acciones comerciales. En este caso se trataba del Carrefour de Alcobendas. Imaginemos que comprobamos que el 60% de nuestros usuarios compran en Carrefour, podríamos unirnos con esta cadena de supermercados para una acción conjunta con la finalidad de buscar gemelos, o para hacer crecer el ticket de compra o realizar estrategias de fidelización a nuestros usuarios.
Localización identificada como lugar de compra habitual
Otra localización clave es el colegio Brains Internacional. Esta persona para habitualmente a la hora de salida del colegio. De inicio nos ayuda a perfilar aún más al usuario y su tipología de hogar, que nos sirve para accionar campañas de crecimiento dentro del usuario con ofertas para perfiles de familia con hijos. También puede ser de utilidad la información pensando en los negocios vinculados al sector de la educación, y por el perfil del colegio podemos deducir que en este caso en concreto la disposición de la familia a invertir en la educación de sus hijos es más alta que la media.
Localización clave identificada colegio Brains Internacional
CONCLUSIONES
Simplemente con un email de registro y la aceptación de la localización la información que podemos sacar es impresionante. Algunas de las conclusiones de las localizaciones identificadas son:
• Vivienda habitual: Nivel socioeconómico alto, potencial cliente de marcas de lujo, posible cliente también de productos y servicios asociados al tenis, pádel, la piscina, accesorios de jardín, sistemas de seguridad. • Lugar de trabajo: Trabaja en la empresa AUTOCARES SANFIZ • Lugar de compra habitual: Compra en Carrefour habitualmente • Lugar de paso habitual identificado como colegio: Familia con hijos, colegio Brains Internacional, dispuesto a invertir en educación.
Esto es una muestra de cómo al recoger datos de localización en el tiempo de un usuario a través de la APP móvil y combinándolo con datos externos de Pyramid Datalake* podemos enriquecer y cualificar usuarios permitiéndonos accionar todo tipo de estrategias de captación, crecimiento y fidelización.
*Los datos enriquecidos en este caso de uso son solo una muestra del potencial de Pyramid Datalake. Existen diferentes datos accionables no contenidos en el caso y se pueden crear nuevos a partir de KPIs a medida.
Jorge González
Responsable de Marketing en DataCentric
CONOCE MÁS ACERCA DEL CASO DE USO ESCUCHANDO A UN EXPERTO
Este sitio web utiliza cookies propias para permitir una navegación segura y adaptar el contenido del sitio web. Igualmente se usan cookies de terceros para analizar la navegación de los usuarios y mostrarte publicidad que sea de tu interés en base a un perfil elaborado a partir de tus hábitos de navegación. Puedes consultar la Política de Cookies.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas. Le informamos de que puede configurar su navegador para bloquear o alertar sobre estas cookies, sin embargo, es posible que determinadas áreas de la página web no funcionen.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.