
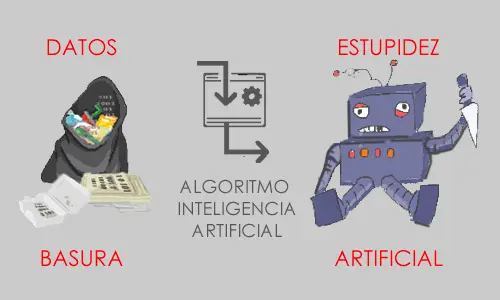
“Garbage in, garbage out” es un concepto clave en informática desde los años 80 y es especialmente valido cuando tomas decisiones basadas en datos.
El marketing de los vendedores de tecnología ha fomentado la idea de que todo era cuestión de adquirir la última versión de sus productos para subirse a la ola del CRM, del Big Data después y de la IA ahora. Sin embargo, los que hemos tragado ya mucha agua salada sabemos que es mejor un Excel con buenos datos y procesos que no una plataforma potentísima con datos no coherentes. Es mejor un modelo basado en simples correlaciones estadísticas testadas y controladas, que no un sofisticado modelo de data science con datos no contrastados.
Al fin y al cabo, el machine learning, la herramienta de IA más común, no es más que un método de análisis de datos que automatiza la construcción de modelos mediante el parseo de datos. Su base de aprendizaje se encuentra en identificar patrones en los datos, hacer predicciones y tomar decisiones con mínima intervención humana.
La potencia de uso del machine learning deriva de la riqueza de datos con los que sea alimentado. Para ello es fundamental que tus modelos de machine learning trabajen con data correcta, no sesgada y coherente que permita a su algoritmia aprender. Peter Norvig, Director de Investigación de Google afirmaba: “No es que tengamos los mejores algoritmos… simplemente tenemos más datos.”
5 pasos para preparar tus datos para procesos de Machine learning:
1. Limpieza y normalización de datos para que sean válidos, completos y coherentes. Para relacionar datos de distintos entornos necesitamos llevarlos a un formato común. No me valdrá de nada mi modelo de datos si los registros están incorrectos. Necesitaré normalizarlos. Este trabajo de fontanería del dato es vital, y en DataCentric tenemos mucha experiencia en trabajos calidad de datos previos a cualquier proceso de fusión de grandes entornos de datos. En muchos casos requerirá el montaje de un Master Data Management.
De la información no nos podemos fiar sin haberla testado. Necesitamos realizar catas sobre datos para estudiar si dan valores coherentes y estudiar resultados no esperados.
2. Plataforma de conexión de datos (APIs). Una vez que tengo mis datos limpios, debo relacionar los distintos entornos de datos a través de los datos maestros generados en la fase anterior. En un entorno de Big Data, la lógica de datos será usualmente distribuida, lo que nos llevará a la necesidad de contar con APIs.
3. Enriquecimiento de datos. La calidad de tus fuentes, definen tus datos. Y sólo con datos internos tienes una muestra sesgada de datos, que obvia todo aquello que no conoces.
DataCentric, en el mercado español, cuenta con más de 2.600 variables diferentes, entre información sociodemográfica, empresarial, comportamental y financiera.
4. Algoritmo y modelización. Nuestros algoritmos de machine learning se entrenarán con los conjuntos de datos limpios y preparados. Es a partir de aquí que el modelo analítico puesto en marcha aprende y se va optimizando.
5. Data Visualization. Para poder entender lo que está sucediendo necesitas pasar de los datos en bruto a datos visualizables, que te permitan sacar y compartir aprendizajes. Ello puede implicar dashboards, mapas o gráficos. A través de la monitorización de los resultados, podemos identificar categorías de datos no válidos o testar si las predicciones del modelo son correctas. Si todo va bien, ya podremos sacar insights sobre lo qué está ocurriendo. A partir de aquí podremos mejorar nuestro modelo o plantear nuevas hipótesis de problemas a solucionar con datos y algoritmia.
Por último, del mismo modo que la Inteligencia Artificial necesita de datos limpios. Asimismo, el Big Data necesita a la IA para poder analizar e interpretar grandes volúmenes de datos desestructurados, como imágenes, logs, videos. Es una relación simbiótica, el Big Data necesita sistemas de Inteligencia Artificial para poder convertir datos en información, valor y negocio para una empresa.
Gerardo Raído
Chief Digital Officer en DataCentric
http://www.linkedin.com/in/gerardoraido
http://twitter.com/gerardoraido



